以Python、PyCharm和PyTorch为基础
提供了有关搭建深度学习单机平台和准备所需软件的概念性普及
开发环境架构:Python 深度学习环境 构建深度学习项目的第一步是理解 Python 开发环境的基本构成。完整的深度学习开发环境通常由以下几个关键组件组成:虚拟环境 、虚拟环境管理系统 、深度学习框架 、软件包管理系统 、软件包 和 集成开发环境 (IDE)等。了解这些概念及其相互关系,有助于更高效地组织开发流程与管理依赖
Python 编程语言 Python 是一种解释型语言,具有简洁的语法和广泛的生态系统,已成为深度学习开发的主流语言。其执行过程为:源代码(.py 文件)首先被解释器编译为字节码(.pyc 文件),随后由 Python 虚拟机(PVM)执行。字节码文件默认保存在 __pycache__ 文件夹中,可加快加载速度并在一定程度上实现源代码保护。
在 Python 生态中,TensorFlow、PyTorch 等深度学习框架以 Python 包 的形式存在,安装后可通过 import 语句引入并使用其提供的功能模块
虚拟环境与管理系统 虚拟环境 是为每个项目构建的隔离运行环境,能避免不同项目之间的依赖冲突。例如,某一项目可能需要 TensorFlow 1.15,而另一个项目使用 TensorFlow 2.x,通过虚拟环境可为两者分别创建独立的依赖环境,互不影响
虚拟环境管理系统 是管理这些虚拟环境的工具,常见的有 Python 官方的 venv、社区开发的 virtualenv,以及集成包与环境管理功能的 conda。它们支持环境的创建、激活、切换与删除
软件包与管理系统 软件包 是用于扩展 Python 功能的功能模块集合,通常包含若干模块、资源文件和说明文档。大多数功能都来源于第三方软件包,例如用于数值计算的 NumPy,用于数据分析的 Pandas 等
软件包管理系统 是用于安装、管理、升级和卸载软件包的工具。在 Python 中,最常用的是 pip(官方工具)和 conda(由 Anaconda 提供)。两者均可用于安装第三方库、深度学习框架或开发工具
Matplotlib :用于绘制静态图像,支持折线图、散点图、柱状图、热力图等数据可视化形式OpenCV :支持图像读取、图像增强、边缘检测、轮廓提取等功能,是工业视觉任务中常用的图像处理库Requests :用于简洁地发送 HTTP 请求,适合网页爬取、API 调用等网络交互类任务软件包管理系统能够大大提升项目开发与环境管理的效率,是 Python 项目开发中的基础工具
深度学习框架 深度学习框架 封装了神经网络构建与训练所需的底层操作,简化了模型开发流程。常用的框架包括:
TensorFlow :由 Google 提供,支持静态计算图与动态图,适合生产部署和大规模训练。PyTorch :由 Meta 推出,采用动态图机制,语法更贴近 Python 原生风格,适合科研和快速迭代这些框架均可通过 pip 或 conda 安装,并通过导入其 Python 包进行模型定义、训练与推理
集成开发环境(IDE) 集成开发环境 (IDE)是集成代码编辑、项目管理、调试器、终端等工具于一体的开发平台,可显著提高开发效率。常用的 IDE 有:
PyCharm :功能强大的 Python IDE,支持智能补全、调试、虚拟环境配置、版本控制等,适合构建中大型深度学习项目Jupyter Notebook :基于 Web 的交互式开发环境,适用于数据分析、可视化与模型实验,常用于教学与快速测试以上各组件共同构成了完整的 Python 深度学习开发环境。合理组织并理解它们之间的关系,有助于提高项目的可维护性与开发效率
框架的差异与选择 没有哪一个框架是“完美”的——就像一盒乐高积木,某些组件可能缺乏你想要的形状。不同框架各有侧重点,适用于不同的应用场景。深度学习框架本质上提供了构建模型所需的基础组件(如网络层、损失函数、优化器等),对于常见算法通常已有封装,遇到新的算法需求时,则需要用户自行定义模块并结合框架 API 使用
因此,在开始项目之前,选好合适的框架至关重要 。一个合适的框架可以大大提升效率,降低开发难度
目前(截至 2023 年),最流行的两个框架是:
框架名称(附 GitHub) 主要维护方 支持语言 特征 TensorFlowGitHub Google C++ / Python / Java / R 等 功能最全面、生态庞大,适合生产部署,学习曲线略陡 KerasGitHub Google Python / R 高层封装易上手,适合快速构建和原型设计 Caffe / Caffe2GitHub / Caffe2 BVLC / Facebook C++ / Python / Matlab Caffe 已停更,Caffe2 并入 PyTorch PyTorchGitHub Meta (Facebook) C / C++ / Python 动态计算图灵活好调试,研究与应用两相宜,最新的研究基本都是基于Pytorch TheanoGitHub UdeM Python 最早期框架之一,现已停止维护 CNTKGitHub Microsoft C++ / Python / C# / .NET / Java / R 微软推出但已停止更新,不建议新项目使用 MXNetGitHub Apache (原 DMLC) C++ / Python / R 等 支持多语言,高性能,Amazon 支持,略小众 PaddlePaddleGitHub 百度 C++ / Python 国内团队主推,工业界应用广,OCR/NLP 支持好 Deeplearning4jGitHub Eclipse Java / Scala JVM 平台首选,适合与大数据生态(如 Spark)集成
深度学习框架并没有“最佳选择”,不同人对框架的偏好可能差异很大,不同任务和开发阶段对框架的需求也不尽相同。同时,框架的流行度也会随着时间不断变化
下面我们对目前主流的三个框架 —— TensorFlow、PyTorch 和 PaddlePaddle —— 从多个维度进行简要比较(初学者可略读):
API 设计 TensorFlow 同时提供低级与高级 API,适合从灵活构建到底层控制。PyTorch 提供模块化的 API,例如 torch.nn、torch.optim,兼顾灵活性与易用性。PaddlePaddle 提供结构清晰的 API,便于上手,适配各类模型开发需求。架构与性能 TensorFlow :功能强大,适合构建复杂、可部署的系统。PyTorch :动态计算图、代码风格简洁,广受研究者青睐。PaddlePaddle :具备良好的可扩展性,支持分布式训练,部署能力强。调试体验 TensorFlow :早期版本调试繁琐,新版本(2.x)已改善许多。PyTorch :原生支持动态图,可直接用 Python 工具(如 pdb、PyCharm)调试。PaddlePaddle :提供 VisualDL 等可视化工具,调试与分析能力突出。应用适用性 TensorFlow :工业级框架,适合大型模型、部署需求强的项目。PyTorch :灵活、简洁,适用于研究、NLP、CV等多种场景。PaddlePaddle :内置大量预训练模型,尤其适合中文场景,适配 OCR、NLP 等工业场景。神经网络支持 PyTorch :对循环神经网络(RNN)支持灵活,可构建复杂序列模型。TensorFlow :支持多种 RNN 单元,封装程度高,适合工程部署。PaddlePaddle :具备丰富的网络组件和良好的模块封装,便于构建各类深度模型。总结 框架 特点简述 TensorFlow 工业级框架,灵活强大、部署能力强 PyTorch 代码清晰、调试灵活、研究界首选 PaddlePaddle 国产框架,适配中文,部署工具链完备
选择哪种框架,取决于你的 项目需求、部署场景 和 个人习惯
ONNX:深度学习模型的中间格式 ONNX(Open Neural Network Exchange) 是一个开放的深度学习模型交换格式,旨在实现不同深度学习框架之间的互操作性。
由 Microsoft 和 Facebook 联合发起 得到 Amazon、Intel、NVIDIA 等大厂支持 本质上是一个“模型通用语言”,不是深度学习框架 ONNX 允许开发者在一个框架中训练模型(如 PyTorch),再导出成 ONNX 格式,在另一个框架中部署(如 TensorRT、OpenVINO、ONNX Runtime),大大提升了模型跨平台部署的自由度
为什么需要虚拟环境? 在 Python 开发中,我们常通过 pip 来安装第三方包,但系统中只能安装每个包的一个版本。如果多个项目依赖于不同版本的同一个库(例如 A 项目需要 numpy==1.23,B 项目需要 numpy==1.19),就容易出现版本冲突,导致项目无法正常运行。
为了解决这个问题,我们引入了 虚拟环境 —— 它能为每个项目创建一个“独立隔离”的 Python 运行环境,互不影响
使用虚拟环境的优势: 不同项目使用不同的库版本,互不干扰 避免污染系统环境,提高稳定性 项目部署更方便(打包更干净) 虚拟环境管理工具对比 工具名 特点简述 Virtualenv 最基础的虚拟环境管理工具,轻量好用,配合 pip 使用 Conda 支持 Python + 多语言环境管理(如 R、C++ 等),集成包管理,适合科学计算场景 Pipenv 官方推荐,整合了 pip + virtualenv,支持自动锁定依赖版本
推荐组合:Conda (更全面)或 Virtualenv + pip (更轻量) Python 包管理工具简介 Python 中的包管理工具主要有两类功能:
安装/卸载 Python 包 (如 pip、conda)管理依赖关系和版本 (如 pip freeze, pipenv lock)常见工具介绍: pip :最常用的 Python 包管理工具,可配合 virtualenv 使用conda :集成虚拟环境 + 包管理,适合科学计算类项目poetry :现代化的包管理工具,依赖控制更清晰,适合中大型项目什么是 Python 包与模块 Python 程序是由 包(Package) 、模块(Module) 和 函数(Function) 组成的:
概念 简要说明 模块 一个 .py 文件即为一个模块 包 包含 __init__.py 的文件夹,表示一个可导入的包 函数 封装具体功能的代码块,可在模块或包中定义
举例说明:
my_project/
│
├── utils/ ← 这是一个包(含 __init__.py)
│ ├── __init__.py
│ ├── image_utils.py ← 模块
│ └── string_utils.py ← 模块
└── main.py ← 主程序
导入方式如:
from utils.image_utils import resize_image
GitHub 项目包常见文件与目录说明 README.mdrequirements.txtpip install -r requirements.txt 命令自动安装setup.py.gitignoreLICENSE.github/ISSUE_TEMPLATE/PULL_REQUEST_TEMPLATE/workflows/.ymlFUNDING.ymlCODEOWNERS常见的集成开发环境(IDE) 集成开发环境(IDE)是将代码编辑器、调试器、终端等工具集成于一体的开发平台,能大幅提升开发效率。常见 Python IDE 如下:
IDE 工具 特点简述 PyCharm JetBrains 出品,功能强大,适合构建复杂项目,支持虚拟环境配置、调试、代码补全等 Jupyter Notebook 交互式 Notebook,适合快速实验、教学、数据分析等场景 Spyder 更偏科学计算领域,支持变量监控、交互式编辑 Visual Studio Code 轻量、插件丰富,适合多语言开发,Python 插件生态成熟
小提醒:PyCharm 会在项目根目录自动生成 .idea 文件夹,用于保存项目的解释器设置和文件配置,不建议随意删除
一些其他核心概念补充 API(Application Programming Interface) :应用程序编程接口,用于软件间通讯和调用。SDK(Software Development Kit) :软件开发工具包,包含文档、代码示例、工具集合等类比:SDK 是一个装好功能的工具箱,而 API 是它留下来的“入口开口” 安装软件时的环境变量(PATH) 在 Windows 中安装软件时,常会遇到“是否加入系统环境变量”的选项。环境变量(特别是 PATH)决定了终端或命令行在运行指令时,到哪里去找可执行程序
例如你安装 Python 后勾选了“添加到环境变量”,就可以直接在命令行(cmd)中敲 python 来打开解释器,否则会报“找不到命令”。
环境变量配置不当,可能导致多个 Python 环境之间冲突(如 Anaconda 与原生 Python 共存)
Anaconda 安装 Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。包含了大量的科学包, 是一个开源的软件包管理系统 和环境管理系统 。正常安装即可,注意在结束后需要确保:
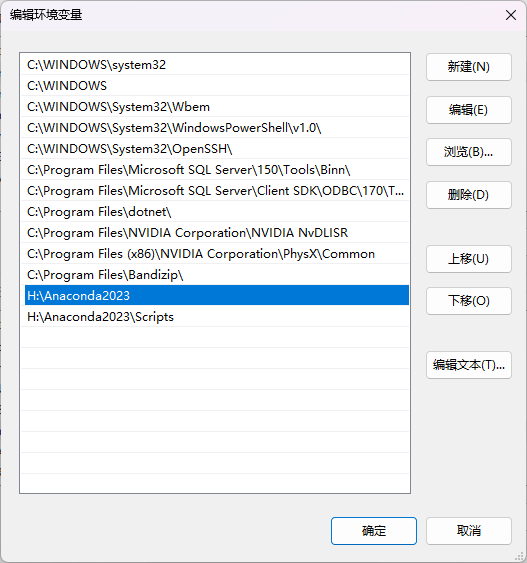
将以下路径添加到 环境变量 系统变量 Path 之中(如果更改了安装路径,自己对应修改下)
D:\ananconda :将Anaconda的根目录路径添加到环境变量,使得系统可以在任何位置访问Anaconda的命令和工具。例如,在命令行中可以直接运行conda和python命令,而不需要指定完整的文件路径D:\ananconda\Library\bin :将Anaconda库目录下的bin路径添加到环境变量,这个路径包含了一些系统库和可执行文件,如某些编译器和工具链。这样,系统可以在需要的时候自动查找这些文件D:\ananconda\Library\mingw-w64\bin :将Anaconda库目录下的mingw-w64\bin路径添加到环境变量,这个路径包含了MinGW-w64工具链的可执行文件。MinGW-w64是一个Windows平台上用于编译和链接C/C++代码的工具集,添加该路径可以让系统在编译C/C++代码时自动查找所需的工具D:\ananconda\Library\usr\bin :将Anaconda库目录下的usr\bin路径添加到环境变量,这个路径包含了一些Unix-like系统下的二进制可执行文件,如make和sh。添加该路径可以让系统在执行相关命令时自动查找这些工具D:\ananconda\Scripts :将Anaconda的Scripts目录路径添加到环境变量,这个目录包含了一些脚本文件和可执行文件,如activate和deactivate命令等。这样,在命令行中可以直接运行这些脚本和可执行文件通过将以上路径添加到环境变量,可以在任何位置使用Anaconda提供的命令、工具和相关文件,而不需要输入完整的路径。例如,可以在命令行中直接运行conda命令来管理Python环境和软件包,或者运行activate命令来激活特定的环境
IDE安装 Anaconda自带若干种已经安装好的IDE,也可以选择一个
PyCharm 安装 PyCharm 是一种Python集成开发环境(IDE),用于开发Python应用程序。它不包含在Anaconda中,但可以从官方网站下载并安装。PyCharm有免费版和专业版可供选择,它是一个独立的应用程序。在使用PyCharm时,我们可以调用conda创建的虚拟环境
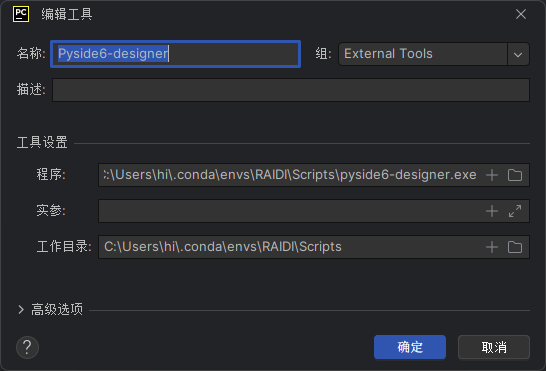
外部工具 在设计应用程序时,我们通常需要使用UI界面框架,如PyQt5或PySide6。为了方便使用UI文件,我们可以直接加载.ui文件或使用工具将其转换为.py文件。同时,资源文件也可以打包为.rcc文件,而不是从本地调用素材资源。因此,我们需要将以下三个工具添加到PyCharm中
Qt Designer:Qt Designer是一个辅助开发工具,用于设计Qt界面 PyUIC:PyUIC是一个工具,用于将Qt Designer设计的.ui文件转换为.py文件 PyRCC:PyRCC是一个工具,用于将图片、数据等资源文件打包成.py文件。通过使用PyRCC,我们可以将资源文件与应用程序一起打包,便于管理和部署 Pyside6-lupdate是一个 国际化支持工具 ,用于从 Python 项目中提取所有待翻译的文本(如 self.tr("文本内容")),并生成 .ts 文件。这些 .ts 文件是 Qt 的翻译源文件,可以交给翻译人员进行语言本地化工作。在配合 pyside6-lrelease 工具使用时,可将 .ts 文件编译为 .qm 文件,供程序运行时加载,实现多语言界面切换。 在安装和配置PySide6开发环境时,可以通过在文件资源管理器中搜索anaconda文件目录下的可执行文件(.exe)来添加工具,或者使用自己安装的工具或虚拟环境中的工具。然而,建议不要将这些工具与特定的项目虚拟环境绑定,以免在删除或移动项目后无法使用。相反,在base环境中安装这些工具,并在PyCharm中进行配置。这样做可以确保这些工具在任何项目中都可用,提供更好的灵活性和可维护性
程序(Program): 程序指的是要执行的命令行工具或脚本 。可以是系统自带的命令行工具(如Python解释器、Git、Pip等),也可以是自定义的脚本文件。程序可以通过指定路径来引用 实参(Arguments): 实参是指传递给程序或脚本的命令行参数 。可以为程序指定一组实参,这些实参将在运行时传递给该程序。实参可以是选项、标志、值等 工作目录(Working Directory): 工作目录是指程序或脚本的当前工作目录 。设置工作目录,以确定程序在执行时的基准位置。程序执行时,相对路径、文件读写等操作将基于该工作目录。如项目根目录,或者使用PyCharm的变量来表示当前项目的目录。 Name:Qt Designer FileDir$ Name:PyUIC FileName$ -o $FileNameWithoutExtension$.pyFileDir$ Name:PyRCC FileName$ -o $FileNameWithoutExtension$_rc.pyFileDir$ Name:Pylupdate FileName$ -ts $FileNameWithoutExtension$.tsFileDir$ Jupyter Notebook 安装 Anaconda预装,是一个Python包,其安装好的快捷方式版本使用方式仅限于Base环境,创建了一个新的虚拟环境中使用Jupyter调用其他项目依赖包需要在虚拟环境下重新安装Jupyter
使用方式 在命令行中先切换到该目录,然后再运行 jupyter notebook 命令。例如:
d:
cd D:\path\to\directory
jupyter notebookCUDA CUDA(Compute Unified Device Architecture)是由显卡厂商NVIDIA于2007年推出的并行计算平台和编程模型。它利用图形处理器(GPU)的计算能力,显著提高计算性能。CUDA采用NVIDIA的通用并行计算架构,使得GPU能够解决复杂的计算问题,并通过编程控制底层硬件进行计算。它包括CUDA指令集架构(ISA)和GPU内部的并行计算引擎,开发人员可以使用C/C++/C++11语言编写CUDA程序
CUDA提供了一种灵活的编程模型,可以通过在主机(CPU)和设备(GPU)之间交互来实现并行计算。开发人员可以使用CUDA的接口函数和科学计算库,以编写并行程序并通过同时执行大量线程来实现并行计算的目标。CUDA的设计使得使用GPU进行通用计算变得简单和优雅
需要注意的是,CUDA并不仅限于图形处理任务,它提供了一种通用的并行计算架构,可用于解决各种复杂的计算问题。通过利用GPU的并行计算能力,CUDA可以在很多领域加速计算,包括科学计算、深度学习、数据分析等
举个具体例子,假设我们有两个向量A = [1, 2, 3, 4]和B = [5, 6, 7, 8],我们想要计算它们的和。使用传统的CPU计算方式,我们需要使用循环迭代遍历每个元素并执行相加操作。但是,这种方式在大规模数据集上效率较低
使用CUDA,我们可以编写一个CUDA程序,将向量A和B传输到GPU上,并编写一个内核函数(kernel function),该函数定义了每个线程执行的操作,即将对应位置的元素相加,并将结果存储在向量C中
在GPU上执行该CUDA程序时,每个线程将并行地执行元素相加操作,最终得到结果向量C = [6, 8, 10, 12]。通过利用GPU的并行计算能力,CUDA实现了高效的向量加法,加速了计算过程
这只是一个简单的示例,实际上CUDA可以应用于更复杂的计算任务,包括矩阵运算、神经网络训练、图像处理等。CUDA提供了丰富的接口函数和科学计算库,使得开发人员可以更方便地利用GPU的并行计算能力来加速各种计算任务
CUDA安装 分为两种情况,一种是深度学习框架在安装过程中自动安装 CUDA 工具包,一种是深度学习框架依赖系统环境中已经安装的 CUDA。下面介绍这两种情况。
对于第一种情况 ,当你使用 pip 或 conda 安装某些深度学习框架(如 PyTorch)的 GPU 版本时,它会自动安装与之兼容的 CUDA 工具包。这意味着你不需要单独安装 CUDA,深度学习框架会自动为你安装所需的 CUDA 版本。
这里插入一下pip安装和conda安装的区别,两者区别不大,个人感觉conda安装类似360软件管家,pip则为官网下载,优先使用pip,维护较好,最好不要混着使用。个人习惯不使用conda 对于第二种情况 ,如果你想在多个深度学习框架中使用 GPU,或者你想使用特定版本的 CUDA,你可以在系统环境中单独安装 CUDA 和 cuDNN。这样,所有的深度学习框架都可以使用已经安装好的 CUDA
CUDA+Pytorch(举例) 这是第一种情况
在选择不同CUDA版本时,PyTorch版本号尾部会出现CUXXX,PyTorch在安装时会自动安装所需的CUDA运行库,用户只需要确保其当前使用的GPU型号支持虚拟环境中PyTorch所需的CUDA版本,并保持向下兼容性即可
如果想在虚拟环境中使用 CUDA 11.3,你需要确保你的 GPU 驱动程序支持 CUDA 11.3。那我们可以先将Base环境的驱动程序升级到11.7,那我在下图创建的虚拟环境中安装了11.3版本的CUDA是没问题的,不需要将显卡的驱动程序支持的CUDA版本一定与虚拟环境的相匹配
CUDA+PaddlePaddle(举例) PaddlePaddle 的安装 包本身并不包含 CUDA。如果你想使用 PaddlePaddle 的 GPU 版本,你需要在安装 PaddlePaddle 之前先安装 CUDA 和 cuDNN
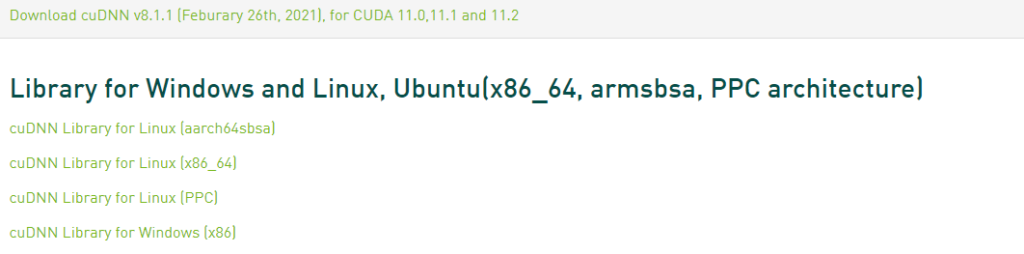
我们看到PaddlePaddle(某项目拿来举例)的CUDA版本是11.2,所以我们找到CUDA的历史版本 ,或者直接pip install 安装cuda,这里记录系统中安装CUDA:
注意,在安装时一定要注意区分是否为GPU版,及对应的版本号
先确认GPU显卡所支持的CUDA版本,打开NVIDIA的控制面板
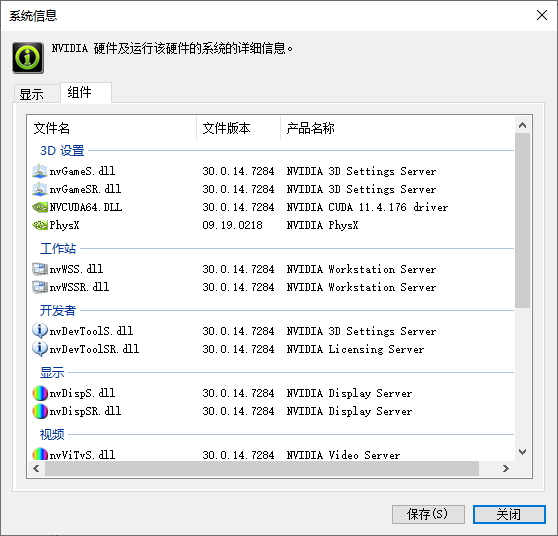
在左下角 系统信息 点击 组件 选项卡
支持到CUDA11.4 支持到CUDA11.4 或者cmd里nvidia-smi
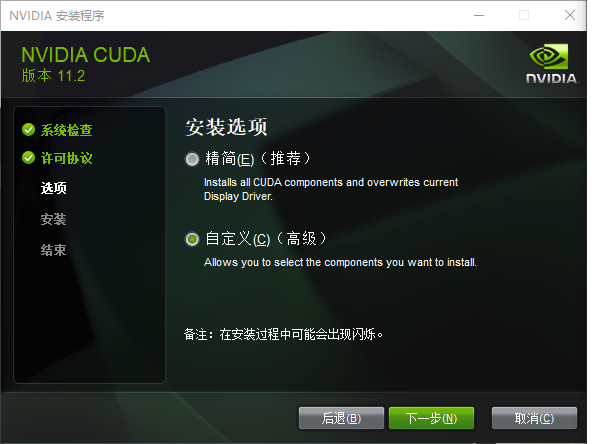
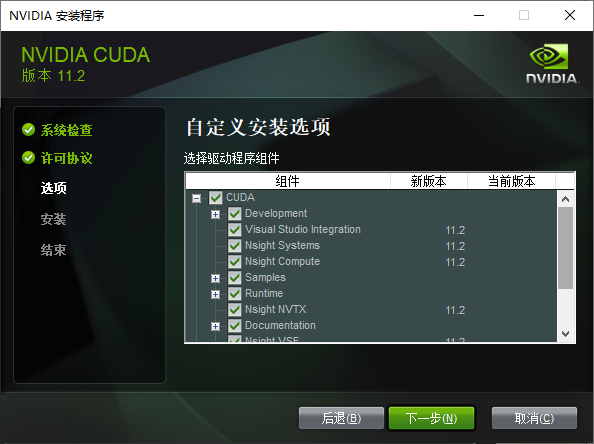
支持到CUDA11.6 支持到CUDA11.6 大部分项目支持的CUDA版本并非最新版,所以我们找到时期的代表版本CUDA,下载CUDA ,选择自定义
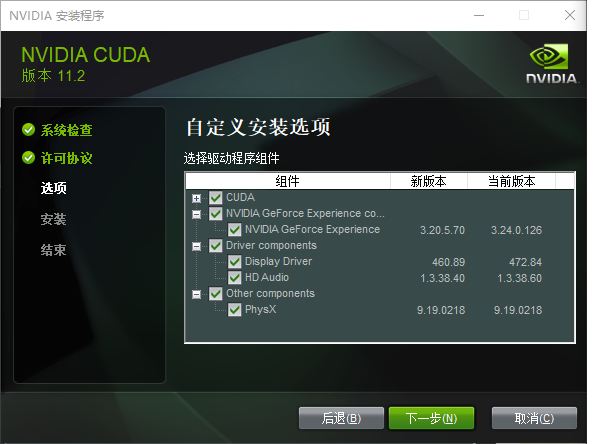
展开选项卡
NVIDIA GeForce Experience:帮助保持驱动程序( 显示驱动程序 )的最新状态,并优化游戏设置
Driver components:显示驱动程序 与 高清音频(在使用支持HD Audio的显卡时,可以通过显示器来传输音频信号)
Other components中PhysX:一种用于模拟和计算物理效果的软件引擎
都安装即可
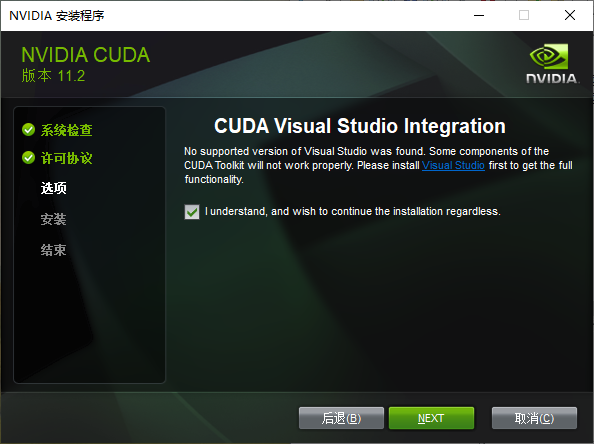
如提示没有Visual Studio,这个是老的CUDA,我们有Visual Studio 2022先不管
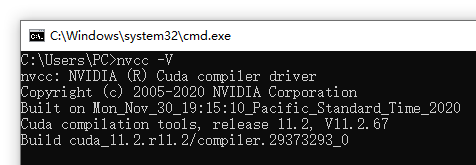
安装成功后,在命令行输入nvcc -V 可以显示cuda的版本信息(有个空格)
如果提错误
我们则找到对应的位置,即C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\extras\demo_suite,然后以管理员身份打开cmd,通过cd命令转换到相应的文件位置,输入上图圈中的命令进行测试,若会显示result=pass,则说明安装无误,那么应该是在安装之后没有设置好系统环境变量,重新设置变量之后(在下面和cudnn一起说)再进行测试
cuDNN 安装 安装了CUDA,获得了使用GPU进行通用计算的能力。然而,CUDA本身提供的函数和算法并不一定针对深度学习任务进行了高度优化。这时候,CuDNN就发挥了作用。
CuDNN是专门为深度神经网络设计的加速库,它针对常见的深度学习操作(如卷积、池化、归一化等)提供了高度优化的实现。它利用了CUDA的并行计算能力和深度学习算法的特点,提供了更高效的函数和算法,从而加速深度学习模型的训练和推断过程。
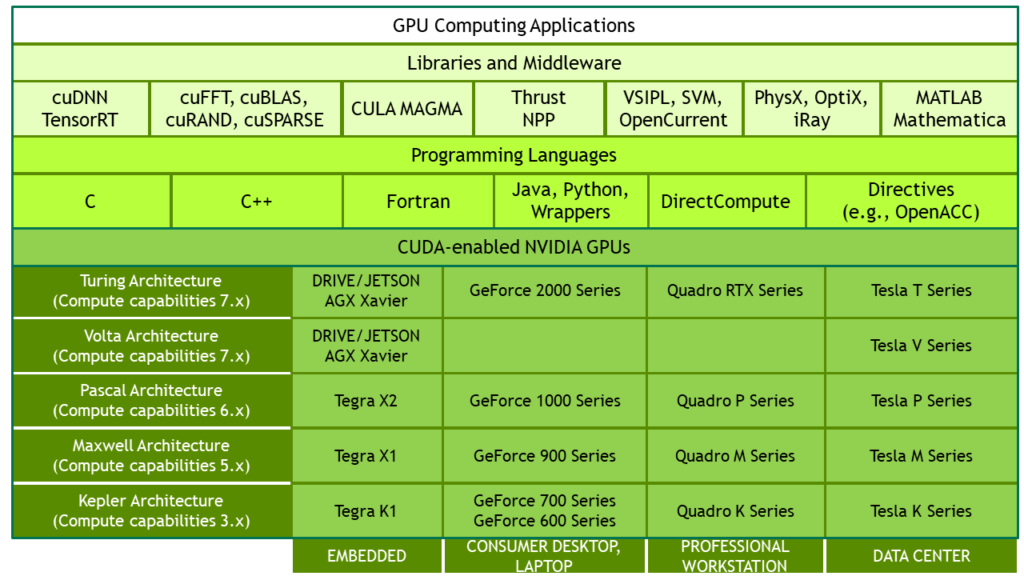
cuDNN(CUDA Deep Neural Network library)是NVIDIA打造的针对深度神经网络 的加速库,是一个用于深层神经网络的GPU加速库。它能将模型训练的计算优化之后,再通过 CUDA 调用 GPU 进行运算。cuDNN需要在有CUDA的基础上进行,cuDNN可以在CUDA基础上加速2倍以上。里面提供了很多专门的计算函数,如卷积等。从CUDA那张图也可以看到,还有很多其他的软件库和中间件,包括实现c++ STL的thrust、实现gpu版本blas的cublas、实现快速傅里叶变换的cuFFT、实现稀疏矩阵运算操作的cuSparse以及实现深度学习网络加速的cuDNN等等,具体细节可参阅GPU-Accelerated Libraries ,安装完CUDA后需要安装对应版本的cuDNN
下载完成后有三个文件夹,将它们分别复制到安装 cuda 的文件夹(默认的化是):C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2 里对应的文件夹 名下即可
将以下路径添加到 环境变量-系统变量 Path 之中(自己对应修改安装路径和版本号)。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\CUPTI\lib64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.2\bin\win64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v11.2\common\lib\x64
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\cudnn\bin
CUDA Toolkit CUDA Toolkit由以下组件组成:
Compiler : CUDA-C和CUDA-C++编译器NVCC位于bin/目录中。它建立在NVVM优化器之上,而NVVM优化器本身构建在LLVM编译器基础结构之上。希望开发人员可以使用nvm/目录下的Compiler SDK来直接针对NVVM进行开发Tools : 提供一些像profiler,debuggers等工具,这些工具可以从bin/目录中获取Libraries : 下面列出的部分科学库和实用程序库可以在lib/目录中使用(Windows上的DLL位于bin/中),它们的接口在include/目录中可获取cudart : CUDA Runtimecudadevrt : CUDA device runtimecupti : CUDA profiling tools interfacenvml : NVIDIA management librarynvrtc : CUDA runtime compilationcublas : BLAS (Basic Linear Algebra Subprograms,基础线性代数程序集)cublas_device : BLAS kernel interface... CUDA Samples ::演示如何使用各种CUDA和library API的代码示例。可在Linux和Mac上的samples/目录中获得,Windows上的路径是C:\ProgramData\NVIDIA Corporation\CUDA Samples中。在Linux和Mac上,samples/目录是只读的,如果要对它们进行修改,则必须将这些示例复制到另一个位置CUDA Driver ::运行CUDA应用程序需要系统至少有一个具有CUDA功能的GPU 和与CUDA工具包兼容的驱动程序 。每个版本的CUDA工具包都对应一个最低版本的CUDA Driver,也就是说如果你安装的CUDA Driver版本比官方推荐的还低,那么很可能会无法正常运行。CUDA Driver是向后兼容的,这意味着根据CUDA的特定版本编译的应用程序将继续在后续发布的Driver上也能继续工作。通常为了方便,在安装CUDA Toolkit的时候会默认安装CUDA Driver。在开发阶段可以选择默认安装Driver,但是对于像Tesla GPU这样的商用情况时,建议在官方 安装最新版本的DriverTensorRT TensorRT是英伟达针对自家平台做的加速包,只负责模型的推理(inference)过程,一般不用TensorRT来训练模型的,而是用于部署时加速模型运行速度ensorRT主要做了这么两件事情,来提升模型的运行速度
TensorRT支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的 2TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,自然就推出了针对自己GPU的加速工具TensorRT。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并 因为不需要更高性能和低延迟的需求,或者需要在实时应用或边缘设备上部署模型,所以没有特别关注TensorRT,仅记录概念
创建虚拟环境 首先明确运行一个项目需要其完整的项目源码 虚拟环境
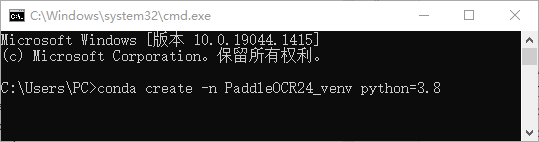
创建虚拟环境 接下来通过anaconda手动创建一个虚拟环境
win+r 打开 cmd
Conda创建环境名:PaddleOCR24_venv(自定义),Python版本:3.8(自定义),该命令会创建1个名为 PaddleOCR24_venv 、python版本为3.8的可执行环境,根据网络状态,需要花费一段时间
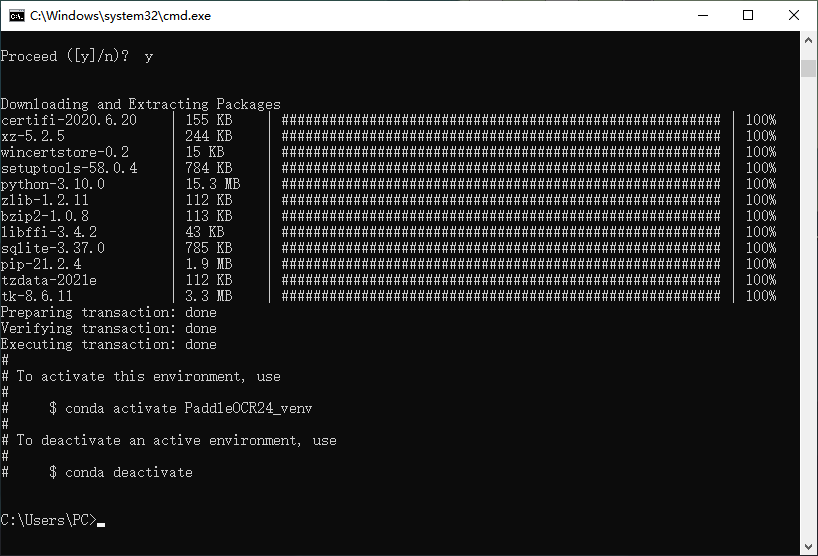
Python相关依赖项(whl包)将会被安装,是否同意, 输入y并回车继续安装
选择同意后将会下载 安装Python=3.8版本的虚拟环境
注意:如果此时挂了代理将会报错,在配置环境过程中需要全程把梯子关掉
显示的诸如certifi-2020.6.20都被称为python包
创建完成后,anaconda非常贴心的提示了我们如何激活 和关闭 虚拟环境
以上anaconda环境和python环境安装完毕
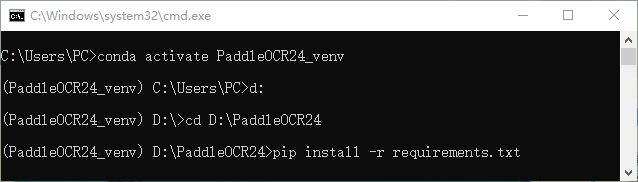
激活虚拟环境 # 激活paddle_env环境
conda activate PaddleOCR24_venv
# 查看当前python的位置
where pythonRequirements.txt 项目所依赖的环境需要依赖大量Python包,所以只有Python的Python包是远远不够的
接下来安装项目所需要 的Python包
一个成熟的项目 会将所需要的Python包整合到源码内的requirements.txt以便于交流和移植
requirements.txt是一个文本文件,通常用于记录一个项目所依赖的所有外部Python包及其对应的版本。每个包及其版本号通常以一行的形式进行记录,使用类似于包名称==版本号的格式。这个文件可以帮助开发者和用户在不同环境中重现项目的依赖关系,确保在安装和部署项目时使用正确的包及其版本
==0.4.0为指定的Python包版本,会优先选择指定版本,没有指定版本的将会选择最新版
因为项目的运行环境可能各不相同,作者只提供了特定环境下的requirements.txt文件。熟悉的用户可能会采取一些额外操作,例如手动屏蔽CPU版本并直接下载GPU版本,或者在包可能为Linux系统的情况下从官方渠道寻找其Windows版本进行下载等,这里就默认下载原有的 requirements.txt 文件内容:
首先定位(cd) 到requirement所在文件夹,随后通过pip install -r requirements.txt 进行安装
安装过程将会通过已经配置好的网络地址 进行下载.whl文件
如果环境充足,可以用tar包或者tar.gz包,如果环境欠缺,比如缺少某些编译环境,或者想要快速且稳定,可以考虑whl包,PIP安装一般都用whl包
同时也可以下载source类型的文件安装,下载的是tar包、tar.gz包,解压后里面有个setup.py文件。虚拟环境下切换到setup.py所在的文件,执行:python setup.py install
pip install -r requirements.txt 的目标是完整的安装完requirements所需要的所有内容,提示Successflly installed即可!
PS:在安装完成后项目即可使用,但是项目是深度学习涉及到神经网络相关,需要用到显卡,这时候可能需要 可能需要
将虚拟环境配置给项目 打开一个新的项目,Pycharm(python IDE)会提示是否创建虚拟环境
我们已经创建好了,所以不用 这种方式创建(目前还未尝试这样方式与anaconda创建的虚拟环境有什么区别)取消
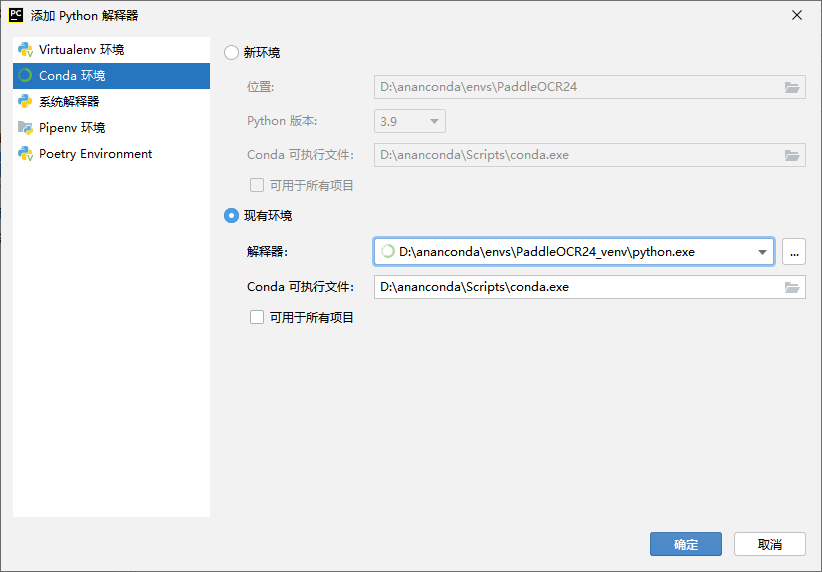
在设置 - 项目 - python解释器中 需要配置项目的Python解释器版本
可以看到指定虚拟环境下已经安装好的Python包,然后确定
可以看到后台正在扫描Python SDK和项目本身,以及收集编码辅助的详细信息,等待索引更新好有项目就可以使用了
可能遇到的报错 Anaconda安装 VSCode 失败 在win10下安装Anaconda时,最后有一步是要安装VSCode,但是在联网正常的情况下提示失败。
# 在anaconda目录下,找到vscode_inst.py文档,第110行原为:
VSCODE_ENDPOINT = 'https://vscode-update.azurewebsites.net/api/update/{}/stable/version'.format(VSCODE_SUBDIR)
# 修改为:
VSCODE_ENDPOINT = 'https://update.code.visualstudio.com/api/update/{}/stable/version'.format(VSCODE_SUBDIR) conda 更换为 清华源 修改镜像源的原因是pip和conda默认国外镜像源,所以每次安装模块pip install ×××或者 conda install ×××的时候非常慢或者遇到以下报错 CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.co 所以,切换到国内的镜像源会显著加快模块安装速度
下面代码为conda更换清华源
文件位置位于 C:\Users\用户名 \.condarc
# 生成.condarc 的文件
conda config --set show_channel_urls yes
# 修改.condarc文件
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
#清除缓存索引
conda clean -i
pypi更换为清华源 pip安装时更换源路径为 C:\Users\用户名 \AppData\Roaming\pip\pip.ini
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
# 注意,simple 不能少, 是 https 而不是 http如果再安装过程中无限出现以下警告,建议换个源
INFO: pip is looking at multiple versions of sanic to determine which version is compatible with other requirements. This could take a while.
INFO: This is taking longer than usual. You might need to provide the dependency resolver with stricter constraints to reduce runtime. If you want to abort this run, you can press Ctrl + C to do so. To improve how pip performs, tell us what happened here: https://pip.pypa.io/surveys/backtracking安装whl包失败 在安装PaddleOCR过程中
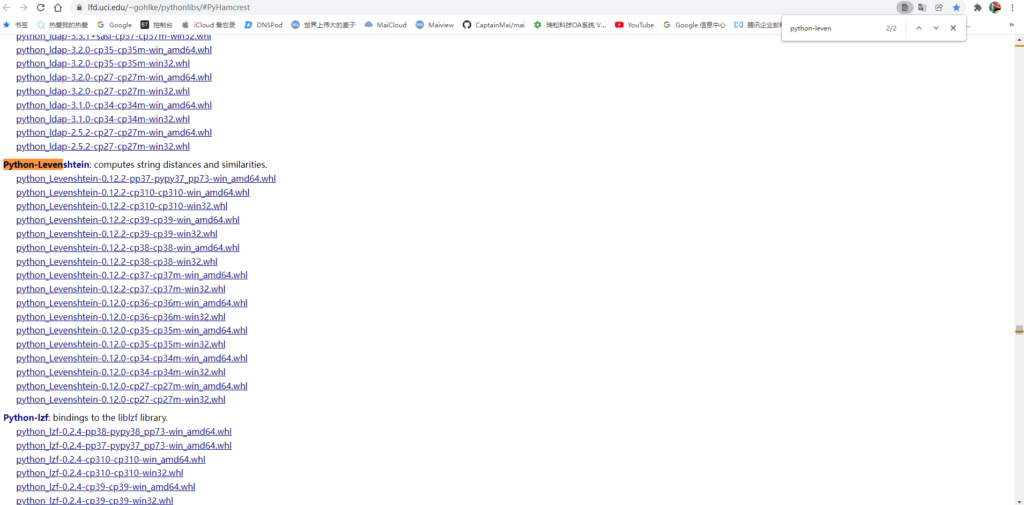
手动安装whl包通过非官方的Python包 进行下载
Ctrl+F找到所需要的whl包
PS:介绍一下文件名格式
文件后缀cp表示Python版本,win_amd64就是64位的
(至于64位版本为什么叫amd64,而不是intel64,因为64位架构是amd公司提出的,amd yes!)
举例:python_Levenshtein‑0.12.2‑cp310‑cp310‑win_amd64.whl 就是需要3.10版本的 64位的系统,然后下就可以了
(小tip:将.whl的后缀改为.zip即可可看到压缩包里面的内容)
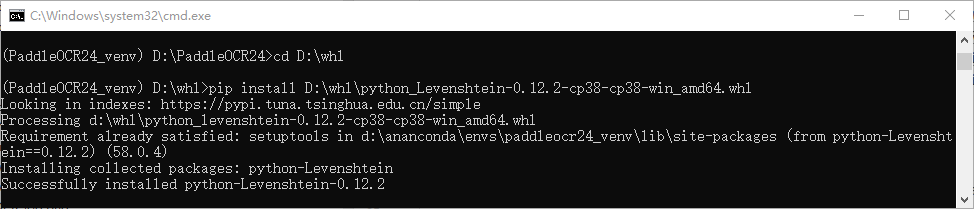
下载对应的whl包然后定位到文件对应目录下 pip install + 文件名安装
解决了错误后可以重复安装一次 requirements.txt进行验证,看是否所有的包都被安装好了
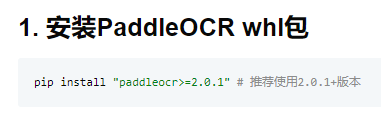
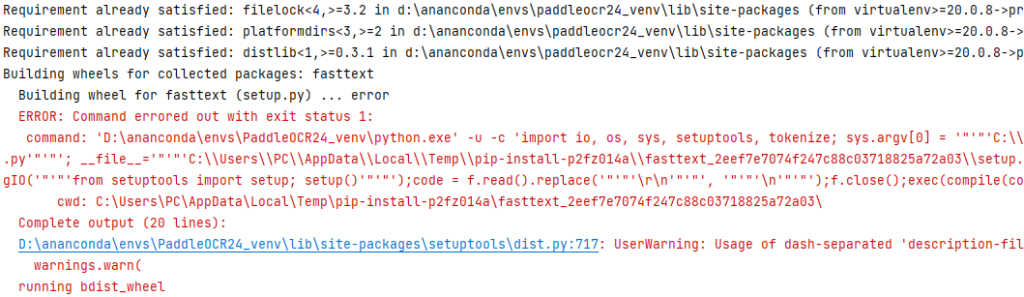
pip安装报错(一) 在安装PaddleOCR过程中
但是我们无论是 pip install paddleocr 或者 pip install paddleocr>=2.0.1 都会报错
提示是fasttext这个包无法正确安装,按照手动下载安装fasttext whl包手动安装的方式也不行,这时候请尝试下载paddleocr的上一个版本,pip install paddleocr==2.3.0.1
在此特别强调一下,我们从GitHub仓库下来的源码和pip install的源码是不同的
二次开发和打包时需注意import的位置
如果再部署好环境后仍然找不到某个模块或者其子项,就重新注意版本
pip安装报错(二) 在安装PaddleOCR过程中
安装Paddle Paddle过程中,需要根据自己的CUDA版本进入官网选择更多版本需求,pip PaddlePaddle-gpu 往往会安装一个错误的版本
在安装某个变种yolo过程中
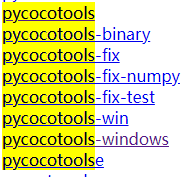
注意不同版本的包运行环境有所不同,比如coco包可能作者是在Mac上运行的文件里直接pycocotools == 2.2但是我们在windows上运行需要注意其变形版本




























Comments | NOTHING