本笔记主要聚焦于基于深度学习的图像处理内容,既是对计算机视觉知识体系的向前扩展,也是对机器学习基础的深入延展。旨在以通俗易懂的方式普及相关核心概念,为后续深入理解深度学习算法在图像领域的应用打下基础
深度学习的研究现状 当前,深度学习(DL,deep learning)已成为人工智能 (AI,artificial intelligence) 领域的重要分支,并与机器学习 (ML,machine learning) 一起构成了现代AI技术体系的核心。其研究与应用方向主要集中在以下三个领域
计算机视觉(CV,computer vision) 自然语言处理(Natural Language Processing, NLP) 语音识别(Speech Recognition) 在这三大领域中,计算机视觉 被认为是深度学习最早实现突破的应用领域之一,尤其在图像识别、图像生成、图像理解等任务上取得了诸多成果。其核心任务可进一步细分为:
图像分类 (Classification):判断一张图片属于哪个预定义类别。例如将图片判定为“猫”或“狗”目标检测 (Detection):在图像中识别出多个目标对象,并给出每个目标的类别与位置图像分割 (Segmentation):对图像中的每一个像素进行分类,实现更加精细的目标边界识别这三项被视为计算机视觉的三大基础任务,也是后续复杂视觉任务(如图像描述、视频理解、三维重建等)的基础
深度学习在图像识别领域研究现状 图像处理是深度学习最早取得重大突破的应用方向之一。早在 1989 年,加拿大多伦多大学的 Yann LeCun 教授(即日后深度学习“三巨头”之一)与其团队首次提出了**卷积神经网络(Convolutional Neural Network, CNN)**的概念。这一模型最初被设计用于手写数字识别,在小规模任务上取得了优异成绩。LeCun 所提出的 LeNet-5 模型
CNN 的设计灵感来源于神经科学,尤其是 Huber 与 Wiesel 对哺乳动物初级视觉皮层(V1 区)的研究成果。早期的 CNN 通常由两层可训练的卷积层、两层固定的池化层以及至少一个全连接层组成,其深度通常超过五层。尽管在特定场景下表现优越,但由于计算资源有限,早期的 CNN 并未在大型图像处理任务中取得突破性进展,也未能引起广泛重视。
直到 2012 年,深度学习的转折点到来。Hinton 教授及其学生 Alex Krizhevsky 设计了AlexNet模型
ReLU 激活函数的引入 :替代传统 Sigmoid/Tanh,提高了训练效率;Dropout 机制 :有效抑制过拟合;数据增强(Data Augmentation) :扩大训练数据规模,提升模型泛化能力;GPU 加速 :首次大规模使用 GPU(NVIDIA GTX 580)进行神经网络训练,使得深层网络的训练时间大幅缩短。AlexNet 的成功,标志着深度卷积网络正式登上主流舞台,也引爆了后续一系列网络结构的创新浪潮,如 VGG、GoogLeNet、ResNet 等。
在国内,以百度、阿里、腾讯为代表的互联网企业也迅速将深度学习技术落地于实际应用中,尤其在人脸识别、图像内容审核、视觉搜索等方向率先部署了基于 CNN 的深度学习系统。可以说,图像识别不仅是深度学习的起点之一,更是其最成熟、最广泛落地的应用场景。
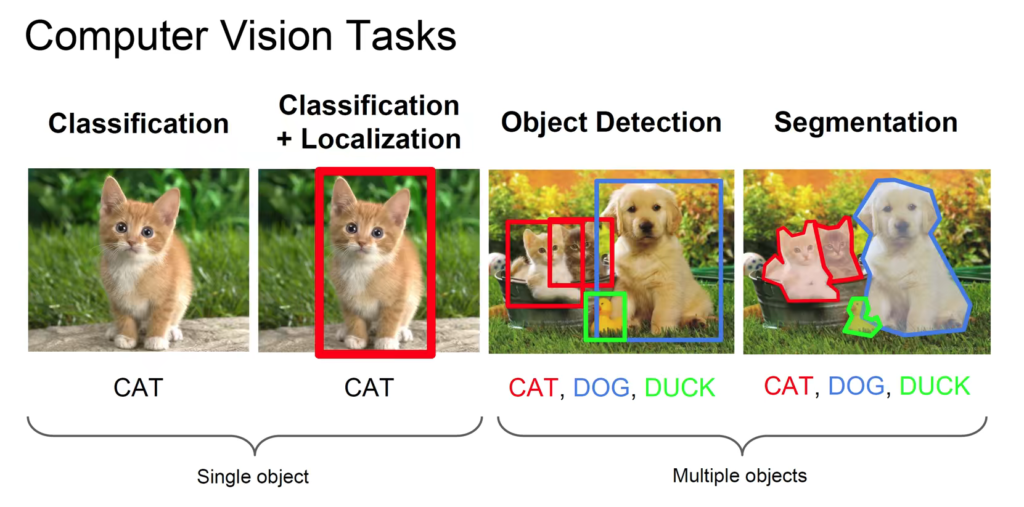
图像理解的三大基础任务:分类、检测、分割 在计算机视觉中,图像分类、目标检测、图像分割是最基础、也是最广泛研究和应用的三个核心任务
分类 分类+定位(一个目标) 目标检测(多个目标) 分割 分类 分类+定位(一个目标) 目标检测(多个目标) 分割 一、图像分类(Classification) : 即是将图像结构化为某一类别的信息,用事先确定好的类别(category)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,
图像分类是最基础的图像理解任务,其目标是:将整张图像归入一个预定义的类别 。早期深度学习的诸多突破正是首先在图像分类任务上取得的,ImageNet 数据集和 ILSVRC 竞赛在其中起到了关键作用。
分类模型的输入是图片,输出是一个标签,例如判断这张图像属于“猫”、“狗”还是“风景”。分类不涉及图像中物体的具体位置,仅仅是对整体内容的判断。
例如:“这是一张猫的照片”,但模型并不知道猫在哪里。
二、图像分类+定位(Classification with Localization):
这是分类的增强版,模型不仅给出类别,同时用一个矩形框标记出该物体的位置 。但它只能找出单个主要目标 的位置,适用于简单场景。
例如:“这是一张猫的照片,猫在这儿”,并画出一个框
三、目标检测(Object Detection) :
目标检测任务要求模型从图像中识别出所有感兴趣的物体,并输出它们的类别与精确位置 。每一个目标都需要被单独识别并框出,因此其输出是多个 bounding box 和对应的类别
目标检测不仅能告诉你图中有哪些物体,还能告诉你“在哪里”、“有几个”。
例如:“图中有两只猫、一只狗,一只鸭子,它们分别在这里、这里和这里。”
经典目标检测算法包括:RCNN 系列(如 Fast RCNN、Faster RCNN)、YOLO 系列(如 YOLOv3/YOLOv5/YOLOv8)、SSD 等
四、图像分割(Segmentation) :图像分割将图像的每一个像素都划分到某个语义类别中,是精度更高的视觉任务
图像分割 分类 目标检测 分割 分类 目标检测 分割 语义分割 (Semantic Segmentation):将图像中所有像素分配给不同的类别,但不区分不同实例 。例如把图中所有“人”标成红色,无论是1个人还是5个人
实例分割 (Instance Segmentation):在语义分割基础上,区分出每个独立的实例 。例如图中有3辆车,模型会给每辆车打上不同的标签
总结类比 任务 输出内容 是否标出位置 是否分辨多个目标 是否像素级 分类 类别 ❌ ❌ ❌ 分类+定位 类别 + 框 ✅ ❌ ❌ 检测 每个物体的类别+框 ✅ ✅ ❌ 分割 每个像素的类别(或实例) ✅ ✅ ✅
工业机器视觉中的传统图像处理方法 在深度学习尚未普及之前,工业机器视觉系统广泛依赖传统图像处理算法来完成目标检测、分割、识别和定位等任务。这些方法通常基于图像的灰度、边缘、纹理或几何形状等低层次特征,具备运行效率高、结果可解释性强、部署简单等优点,尤其适合嵌入式设备或对实时性要求较高的工业场景。
常见的传统方法包括以下几类:
阈值分割(Thresholding) :将像素灰度值与设定阈值进行比较,区分前景与背景。适用于目标与背景对比明显的场景,例如在 LED 灯检测中,使用固定阈值分离发光区域和非发光区域。边缘检测(Edge Detection) :检测图像中灰度变化剧烈的区域以提取物体边界,常用算子包括 Sobel、Canny、Prewitt 等。例如在螺丝尺寸测量中,边缘检测常用于获取边缘轮廓,从而进行长度或角度计算。分水岭算法(Watershed) :将图像视为地形图,使用“水流扩展”思想将图像划分为多个区域,适合处理粘连目标,如药片计数或工业螺母的分离检测。聚类分割(如 K-means) :将图像像素根据颜色、亮度或纹理划分为不同类别区域。例如在 PCB 板图像中,根据颜色聚类分离焊点区域与线路区域。区域生长(Region Growing) :从种子点出发,根据像素相似性逐步扩展区域。例如在工业涂层检测中,区域生长可用于判断是否存在破损或脱落区域。图论分割(如 GraphCut) :将图像建模为图结构,通过最小割算法获得全局最优分割结果。常用于需要手动交互式标注的半自动缺陷提取,如在焊缝检测中预标记前景与背景后进行精细切割。基于纹理或特征提取(如 HOG、Gabor) :通过提取纹理方向或局部梯度直方图信息,配合分类器判断区域特征。例如在金属表面划痕检测中,HOG 特征可用于识别划痕方向性。此外,工业视觉系统中还广泛使用模板匹配(Template Matching) 技术,特别在 Halcon、VisionPro 等商业视觉平台中非常常见。模板匹配属于目标定位类方法,其原理是滑动一个模板图像(即标准样本)在目标图像上,并计算每个位置的相似度得分,以找出最匹配的位置。
常用的相似度计算方式包括:
SSD(Sum of Squared Differences,平方差和) :将模板图像与目标区域对应像素做差并平方求和,SSD 越小表示越相似。优点是实现简单,计算快,适合实时场景,但对光照变化敏感。NCC(Normalized Cross-Correlation,归一化互相关) :对模板和目标区域进行归一化后计算相关系数,NCC 越接近 1 表示越相似。相比 SSD 更能抵抗亮度变化,但计算略复杂。模板匹配常用于目标形状稳定、姿态变化小的任务,如字符识别、标签定位、装配件对位检测等。然而在存在旋转、尺度变化或遮挡的情况下,传统模板匹配方法鲁棒性较差
综上所述,传统图像处理方法在许多工业检测场景中仍具有不可替代的优势,尤其在实时测量、规则明确、光照环境可控的条件下,凭借其高效、稳定、可解释的特性,依然是主流解决方案之一
但随着深度学习的发展,图像处理逐渐从手工设计规则转向端到端的数据驱动学习。以 U-Net、Mask R-CNN 等网络为代表的图像分割模型,能够自动学习特征,在处理复杂背景、模糊边缘、多类别干扰等问题时表现出更强的鲁棒性与泛化能力
需要强调的是,传统方法与深度学习并非二元对立,而是互为补充:前者在高精度测量、控制性任务中更为可靠,后者则在复杂、非结构化场景中展现出明显优势。在实际工业项目中,融合两者的“规则+学习”混合范式,正逐渐成为新一代智能视觉系统的主流趋势
人工智能(Artificial Intelligence,AI) 人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,致力于研究如何使机器具备模拟、延伸、甚至超越人类智能的能力。它包含一系列用于模拟人类思维、学习、决策等过程的理论、方法、技术及应用系统,是现代信息科技发展的关键方向之一
官方概念 人工智能是关于构建“能思考”的程序的科学,涵盖逻辑推理、知识表示、学习、自主决策、感知与动作控制等多个方面,目标是使计算机能够完成传统上需要人类智能才能胜任的任务
通俗解释 人工智能是关于构建“能思考”的程序的科学,涵盖逻辑推理、知识表示、学习、自主决策、感知与动作控制等多个方面,目标是使计算机能够完成传统上需要人类智能才能胜任的任务
举例 语音助手(如 Siri、小度、小爱)能听懂并回答问题; 自动驾驶汽车可以识别红绿灯、行人、车道线并自动决策; 医疗 AI 可以辅助医生诊断 CT、MRI 图像中是否存在异常; 推荐算法能根据你浏览记录推送你可能感兴趣的内容。 Azure学习文档中的例子:平衡野生动物保护和经济发展需求需要准确监测受保护的濒危物种的数量。 依靠人类专家正确识别所涉及的动物或在足够长的时间内监测大片区域以获得准确的计数可能并不可行。 事实上,人类观察员的参与可能会让动物不敢出没,影响监测效果。 在这种情况下,可以训练一个预测模型,用它来分析由分布在远程位置上的运动激活摄像机拍摄的图像数据,预测照片中是否有这种动物出现。 然后,可将该模型用于软件应用程序中,该应用程序可对动物的自动识别做出响应,以跟踪大面积地理区域内的动物出没情况,识别种群密集区域,并可将这些区域列为候选保护区(机翻)
该领域的研究包括 人工智能包含多个分支方向,主要包括:
机器人技术(Robotics):涉及感知、运动、决策与路径规划等; 语言识别(Speech Recognition):将语音转换为文字; 图像识别(Image Recognition):识别和分析图像中物体与场景; 自然语言处理(NLP):使计算机“读懂”“写出”自然语言; 专家系统(Expert Systems):模仿人类专家进行问题推理和判断 功能 说明 视觉感知 能够使用计算机视觉功能接受、解释和处理图像、视频流和实时摄像机的输入信息 文本分析 能够使用自然语言处理 (NLP)“读取”基于文本的数据,并可从中提取语义 语音 能够将语音识别为输入,并能合成语音输出。 将语音功能与对文本应用 NLP 分析的功能相结合后,实现了一种称为“对话式 AI”的人机交互形式,在这种形式中,用户可以与 AI 代理(通常称为“机器人”)进行交互,就像与真人交互那样 进行决策 能够利用过去的经验和学习的相关性来评估情况和采取适当措施。 例如,识别传感器读数异常,并采取自动措施防止故障或系统损坏
Azure学习文档中概述的人工智能 机器学习(Machine Learning,ML) 官方概念 机器学习是人工智能的一个核心分支,关注如何通过算法使计算机系统从数据中学习规律,并在没有明确编程指令的情况下,完成预测、分类、判断等任务。其本质是让机器通过大量数据自动建立数学模型 ,以此实现“自我进化”和“智能决策”
通俗解释 人类是通过经验学习的,比如你看到很多次猫,你大概知道什么是猫。机器学习也是类似的:给计算机足够多的样本数据,它就能“学”出规律,从而自己去判断新的数据 。不再需要你手动写规则、判断逻辑,而是交给模型自己去“总结经验
举例说明 比如我们有 10000 张猫的照片(正样本)和 10000 张其他动物的照片(负样本),机器学习模型会通过训练过程自动学会“什么是猫”,并在看到新照片时告诉你:“这是猫”或者“这不是猫”
机器学习与人的相似性 机器学习与人的相似性 遵循的步骤 第一步是导入我们的数据(import the Data
接下来我们要清洗数据(Clean the Data ) 。比如是否有重复、缺失或不合法的内容,如果有,我们不能直接把它们喂给模型。否则,模型可能会从这些“脏数据”中学到错误的模式,最终影响预测效果
有了干净的数据集,我们需要将其划分为训练集和测试集(Split the Data into training / test sets ) 。
第四步是选择一个合适的算法并构建模型(Create a Model )
然后我们要训练模型(Train the Model ) ,也就是把训练集喂给模型,让它从中“找规律”。比如模型可能会自动发现“有胡须 + 三角耳朵 = 猫”的概率更大,这个过程就是参数的学习和权重的更新
模型训练完后,我们可以让它进行预测(Make Predictions ) 。回到猫狗分类的例子,我们给模型一张从未见过的图片,模型会判断它是猫还是狗。预测结果可能对,也可能错 —— 所以接下来就该**评估和优化(Evaluate and Improve
评估的方式包括看准确率(Accuracy)、精确率(Precision)、召回率(Recall)等指标,判断模型表现是否符合预期
最后一步是微调模型(Finetune ) 。这可以包括修改算法的超参数(如学习率、树深等),甚至更换模型本身。我们要不断试错,找出最适合当前任务的那一套组合方式
重点来了:
从预测值的类型上,可以将机器学习任务分为两类:
预测连续数值 = 回归(Regression) 预测离散类别 = 分类(Classification) 回归和分类是机器学习可以解决两大主要问题
传统的机器学习算法,像是在指纹识别、基于 Haar 特征的人脸检测、基于 HoG 特征的物体检测等应用中,已经可以满足一定商业化需求,尤其是在一些特定场景下,表现非常稳定
机器学习与传统编程的区别 传统视觉算法依赖的是“硬编码”,也就是说,开发者需要先人为分析图像的规律,然后写好规则,把图像的关键特征提取出来,比如边缘、颜色、形状等等人起主导作用 ,机器只是“执行者”
相比之下,机器学习的核心思想是:让机器通过数据自己总结规律,而不是人告诉它怎么做 人负责提供样本,机器负责自己学
也就是说
程序员无法预先知道输入 和输出 之间的对应的数学模型和相应的参数、逻辑关系的场合 或者输入与输出之间本身就没有一个统一的公式、公式也难以定义时→ 这时候机器学习就派上了用场 机器学习的过程 学习内容:数据集 在当今的数字社会,我们每天都在生成大量数据:
数据科学家可以利用这些数据,训练出可以预测和判断的新一代模型,这些模型的本质是:在庞大数据中寻找规律,并学会“举一反三”。 c
这些用于训练模型的数据,在机器学习中被称为 “数据集(dataset)” 。“样本(sample)” 。
训练集(Training Set) :模型用来学习规律的“教材”。验证集(Validation Set) :用来调试和评估模型在训练过程中表现的“模拟考试卷”。测试集(Test Set) :最终检验模型泛化能力的“期末试卷”训练集 机器学习中这三种数据集合非常容易弄混,特别是验证集和测试集
训练集是最好理解的,用来训练模型内参数的数据集,迭代优化目标函数,分类器直接根据训练集来调整自身获得更好的分类效果
用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数 超 参数是一个参数,其值用于控制学习过程。相比之下,其他参数(通常是节点权重)的值是通过训练得出的),根据几组模型验证集上的表现决定哪组超参数拥有最好的性能(模型在训练过程中不会‘学习’验证集标签,只用于评估表现)
同时验证集在训练过程中还可以用来监控模型是否发生过拟合 下文有图非常直观 ),一般来说验证集表现稳定后,若继续训练,训练集表现还会继续上升,但是验证集会出现不升反降的情况,这样一般就发生了过拟合。所以验证集也用来判断何时停止训练
测试集用来评价模型泛化能力( 把学习到的内容,应用到新的领域的能力 )
形象上来说 训练集 就像是学生的课本,学生 根据课本里的内容来掌握知识, 验证集 就像是作业,通过作业可以知道 不同学生学习情况、进步的速度快慢,而最终的 测试集 就像是考试,考的题是平常都没有见过,考察学生举一反三的能力
训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力,这样一些 对课本死记硬背的学生(过拟合)将会拥有最好的成绩,显然不对。同理,由于验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型,就像刷题库的学生也不能算是学习好的学生是吧。所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力
在这里记录一些数据集获取的途径:
VOC与COCO数据集 同时,深度学习常用的数据集有VOC数据集和COCO数据集两种
PASCAL VOC挑战赛是一个世界级的计算机视觉挑战赛,在VOC数据集中主要有 Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification 这几类子任务。PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,总共 20 个小类(加背景 21 类)
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类
train_2017:http://images.cocodataset.org/zips/train2017.zip val_2017:http://images.cocodataset.org/zips/val2017.zip test_2017:http://images.cocodataset.org/zips/test2017.zip 训练集和验证集的标签:
http://images.cocodataset.org/annotations/annotations_trainval2017.zip 学习教材:数据标注 在机器学习领域,数据集对应的标准答案,科学家们称之为“数据标注”
定义这些这些标准答案的过程,称为“打标签”
学习教材:数据标注 在机器学习领域,数据集中每一个样本对应的“标准答案”被称为数据标注 (Labeling),而定义这些答案的过程通常叫作打标签 (监督式学习)
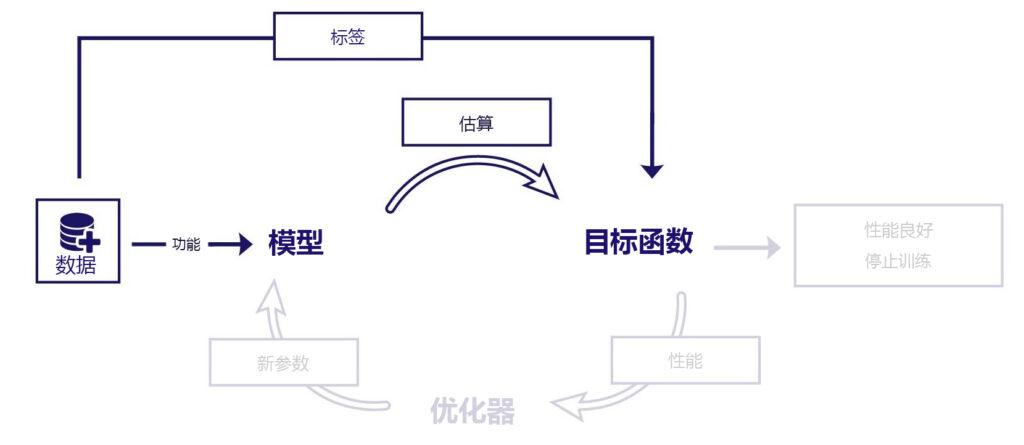
教学对象:机器的学习模型 在训练过程中,模型会根据数据样本不断调整自身的数学结构 ,以期获得尽可能准确的预测能力。这个过程依赖于一个用于衡量预测效果的函数,叫作损失函数 或成本函数 ,而训练目标则是优化这个函数,也就是最小化误差 或最大化收益
在实际训练中,我们优化的对象被称为目标函数(Objective Function) 。目标函数是一个更广义的概念,通常包括模型预测误差和一个用于控制模型复杂度的正则化项
我们来区分几个常见术语:
损失函数(Loss Function): 衡量单个样本预测值与真实值之间差距的函数成本函数 / 代价函数(Cost Function): 所有样本的损失函数的平均值或总和,用于评估模型整体表现目标函数(Objective Function): 通常由成本函数 + 正则化项组成,是整个训练过程中实际被优化的函数目标函数并不一定是要最小化的函数,有些任务中目标函数可能是要最大化,比如最大化后验概率、最大化奖励值等
常见的目标函数类型包括(部分也是成本函数的具体实现):
最大化后验概率 MAP(如朴素贝叶斯) 最大化适应度函数(遗传算法) 最大化回报/值函数(强化学习) 最大化信息增益或最小化纯度(如 CART 决策树) 最小化平方差误差(线性回归、神经网络) 最小化信息熵或最大化 log-likelihood(分类模型) 最小化 hinge 损失函数(支持向量机 SVM) 如果以上术语听起来有些混乱,我们可以总结如下:
损失函数 是用于计算单个样本误差的基础单位;成本函数 是所有损失函数的聚合;而目标函数 是用于模型训练时的最终优化目标
需要注意的是,在不同的论文、书籍或研究机构中,这些术语的使用可能会略有不同,有时会混用。但无论叫法如何,它们的本质都是为了解决一个问题:模型到底学得好不好,我们该怎么衡量?
比较两个成本函数 我们以最常见的两个成本函数来举例:
SSD(Sum of Squared Differences,平方差之和): 对预测值与真实值之差的平方求和,适用于对异常值敏感的回归任务SAD(Sum of Absolute Differences,绝对差之和): 对差值直接取绝对值再求和,抗异常能力更强,但在梯度计算中不如SSD平滑让我们比较一下两个成本函数如何影响模型拟合
这些成本函数描述了拟合模型的“最佳”方式
模型训练过程中还引入了一个重要概念:优化器 。优化器的作用是根据损失值对模型的参数进行更新,从而提升预测准确性。它会评估模型输出与真实值之间的误差(即成本),并基于目标函数推荐更优的参数组合
例如,假设一个环保组织希望开发一款能识别野花种类的手机应用。以下动画展示了这一过程如何通过机器学习实现:
一个由植物学家和科学家组成的团队收集有关野花样本的数据(数据) 并对样本的物种进行正确标记(标注,打标签:是用“基本事实”来注释图像的过程) 使用算法对标记的数据进行处理,该算法可以找出样本特征与标记的物种之间的关系(训练,优化迭代目标函数) 该算法的结果内嵌在模型中(模型) 志愿者发现新样本后,该模型可以正确识别物种标记(推理)
学习方式 监督式学习(supervised learning) 监督学习有四个关键组成部分:数据、模型、成本函数和优化器 监督学习有四个关键组成部分:数据、模型、成本函数和优化器 监督式:有标签数据,(用人为确定的基本事实)输入模型,并增强泛化能力(模型对新鲜样本的适应能力)
学习:用大量参数对数据集进行非线性拟合的过程
可以将监督式学习看作是根据示例进行学习。输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果, 监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,优化器
特征,作为输入提供给模型 (邮件,数字,电脑) 标签,即希望模型能够生成的正确答案 (垃圾邮件,3,联想电脑) 常见算法 监督式学习的常见应用场景是分类问题 (猫还是狗)和回归问题 (天气预测) ,常见算法有:
决策树和随机森林 K-邻近算法(KNN) 支持向量机(SVM) 逻辑回归(Logistic Regression) 朴素贝叶斯 集成学习 LSTM BP神经网络(Back Propagation Neural Network) CNN模型 线性回归(Linear Regression) 非监督式学习(unsupervised learning) 在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构
我们训练模型来解决我们并不知道正确答案的问题。 事实上,非监督式学习通常用于那种没有正确答案而只论解决方案好坏的问题
比如你想让模型画出逼真的搜救犬图像,但没有“正确答案”可供参考。只要生成的图像看起来像狗 ,就能视为较好的结果。此时目标函数也更复杂,可能需要集成一个“狗识别器”来衡量结果是否真实
无监督学习处理的是无标签或结构未知的数据 。用无监督学习技术,可以在没有已知结果变量或奖励函数的指导下,探索数据结构来提取有意义的信息。例如无监督学习应该能在不给任何额外提示的情况下,仅依据所有“猫”的图片的特征,将“猫”的图片从大量的各种各样的图片中将区分出来
在猫的识别中,我们来尝试提取猫的特征:皮毛、四肢、耳朵、眼睛、胡须、牙齿、舌头等等。通过对特征相同的动物的聚类,可以将猫或者猫科动物聚成一类。但是此时,我们不知道这群毛茸茸的东西是什么,我们只知道,这团东西属于一类,兔子不在这个类(耳朵不符合),飞机也不在这个类(有翅膀) 有很多违法行为都需要”洗钱”,这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样? 常见算法 非监督式学习常见的应用场景包括关联规则的学习以及聚类等 ,常用算法有
Apriori算法 k均值聚类算法(k-Means算法) 高斯混合模型(GMM) 层次聚类 密度聚类 谱聚类 监督监督学习与非监督学习的最大区别在于是否依赖目标函数中的真实标签进行训练
半监督式学习 半监督学习是一种结合了少量有标签数据 和大量无标签数据 的机器学习方法
它不像监督学习那样完全依赖标签,也不像无监督学习那样完全不依赖标签,而是处于二者之间,不上不下,但极为实用 。
半监督学习的逻辑就是: 先用少量标签+一堆无标签数据 → 得出一个初步模型 →然后用这个模型去“猜”那些未标记的数据 →再用这些“猜”的结果反过来继续训练自己 →模型一步一步变聪明
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归 ,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
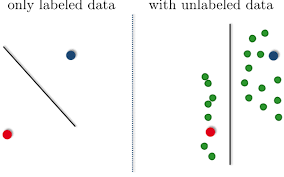
假设上图中红点和蓝点表示两类数据class1,class2。绿点表示没有被标记的数据。如果现在我们用支持向量机(SVM),仅对有标记的数据分类,那么分割线如左图所示。但是其实真是情况是,如果我们不忽略为做标记的数据,数据的分布其实是如右图所示的。那么一个更好的划分线也应该是如右图所示的垂直线。这就是半监督学习的基本原理
常见算法 图论推理算法(Graph Inference) 拉普拉斯支持向量机(Laplacian SVM.)等 强化学习(Reinforcement Learning) 灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,(强化学习的反馈并非标定过的正确标签或数值,而是奖励函数对行动度量的结果。智能体可以与环境交互完成强化学习,并通过探索性的试错或深思熟虑的规划来最大化这种奖励)在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整
(举例)计算机实现从一开始什么都不懂,脑袋里没有一点想法,通过不断地尝试, 从错误中学习,最后找到规律,学会了达到目的的方法。这就是一个完整的强化学习过程。实际中的强化学习例子有很多,比如有名的 Alpha go,机器头一次在围棋场上战胜人类高手,让计算机自己学着玩经典游戏 Atari,这些都是让计算机在不断的尝试中更新自己的行为准则,从而一步步学会如何下好围棋,如何操控游戏得到高分
(补充)采用的是边获得样例边学习的方式,在获得样例之后更新自己的模型,利用当前的模型来指导下一步的行动,下一步的行动获得reward之后再更新模型,不断迭代重复直到模型收敛。在这个过程中,非常重要的一点在于“在已有当前模型的情况下,如果选择下一步的行动才对完善当前的模型最有利”,这就涉及到了两个非常重要的概念:探索(exploration)和开发(exploitation),exploration是指选择之前未执行过的actions,从而探索更多的可能性,exploitation是指选择已执行过的actions,从而对已知的actions的模型进行完善
强化学习作为一个序列决策(Sequential Decision Making)问题,它需要连续选择一些行为,就是代理(Agent)和环境(Environment)在一个时间序列的循环里相互作用的过程。 从这些行为完成后得到最大的收益作为最好的结果。代理会通过当时所处的环境和奖励[State,Reward]来采取行动。生成下一个阶段的状态(state)并反馈奖励(Reward)。代理的终极目标(Goal of Agent)是所有未来奖励之和最大化 (maximize Expected Sum of all future Rewards)。 它在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈
智能体(Agent): 强化学习的本体,作为学习者或者决策者。执行命令的个体 环境(Environment): 强化学习智能体以外的一切,主要由状态集组成。个体执行命令所在的物理世界 状态(States): 表示环境的数据。状态集是环境中所有可能的状态。个体当前所处的环境 动作(Actions): 智能体可以做出的动作。动作集是智能体可以做出的所有动作。代理采取的行动 奖励(Rewards): 智能体在执行一个动作后,获得的正/负奖励信号。奖励集是智能体可以获得的所有反馈信息,正/负奖励信号亦可称作正/负反馈信号。每个行动,环境反馈给的奖励(有正奖励和负奖励) 策略(Policy) : 强化学习是从环境状态到动作的映射学习,该映射关系称为策略。通俗地说,智能体选择动作的思考过程即为策略。 如果让代理根据不同的环境采取不同的行动 目标(Value) : 智能体自动寻找在连续时间序列里的最优策略,而最优策略通常指最大化长期累积奖励。 在某个环境下采取某种行动带来的未来价值 P = 一个由状态 - 行动的函数,意即:这函数对给定的每一个状态,都会给出一个行动
可以把强化学习看作一个与监督学习相关的领域
常见算法 强化学习常见的应用场景包括动态系统以及机器人控制等,算法包括
Q-Learning 时间差学习(Temporal difference learning) 总结 监督学习 vs 无监督学习 最普遍的一类机器学习算法就是分类(classification),对于分类,输入的训练数据有特征(feature),有标签(label)
学习的本质就是找到特征和标签间的关系(mapping)。这样当有特征而无标签的未知数据输入时,我们就可以通过已有的关系得到未知数据标签
在上述的分类过程中,如果所有训练数据都有标签,则为有监督学习(supervised learning)。如果数据没有标签,显然就是无监督学习(unsupervised learning),如聚类(clustering)
强化学习 vs 监督学习 强化学习和有监督学习的主要区别在于:
有监督学习的训练样本是有标签的,强化学习的训练是没有标签的,它是通过环境给出的奖惩来学习 有监督学习的学习过程是静态的,强化学习的学习过程是动态的。这里静态与动态的区别在于是否会与环境进行交互,有监督学习是给什么样本就学什么,而强化学习是要和环境进行交互,再通过环境给出的奖惩来学习 有监督学习解决的更多是感知问题,尤其是深度学习,强化学习解决的主要是决策问题。因此有监督学习更像是五官,而强化学习更像大脑 举例
有监督学习:分类器 无监督学习:自动聚类 增强学习:学下棋 实际运用 在企业数据应用的场景下, 大家最常用的可能就是监督式学习和无监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。 而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域





















Comments | NOTHING